1. Analysis#
analysis gives some examples of matrices decomposition, feature extraction, selection, etc.
Note
Most of the analysis functions have a parameter view . Setting the view parameter to True will give a basic visualization.
1.1. Decomposition: decomposition#
Steps behind the principal component analysis (PCA) and matrices decomposition
1.1.1. Extract PCA: extract_pca()#
A naive approach to extract PCA from training set \(X\). Indeed, the PCA directions are highly sensitive to data scaling and we need to standardize the features before PCA if the features were measured on different scales and we assign equal importance to all features. Moreover, the NumPy function was designed to operate on both symmetric and non-symmetric squares matrices. However you may find it returns complex eigenvalues in certain cases related function, numpy.linalg.eigh has been implemented to decompose Hermitian matrices which is numerically more stable to work with matrices such as the covariance matrix. numpy.linalg.eigh always returns real eigh eigenvalues
>>> from watex.exlib.sklearn import SimpleImputer
>>> from watex.utils import selectfeatures
>>> from watex.datasets import fetch_data
>>> from watex.analysis import extract_pca
>>> data= fetch_data("bagoue original").get('data=dfy1') # encoded flow categories
>>> y = data.flow ; X= data.drop(columns='flow')
>>> # select the numerical features
>>> X =selectfeatures(X, include ='number')
>>> # imputed the missing data
>>> X = SimpleImputer().fit_transform(X)
>>> eigval, eigvecs, _ = extract_pca(X)
>>> eigval
array([2.09220756, 1.43940464, 0.20251943, 1.08913226, 0.97512157,
0.85749283, 0.64907948, 0.71364687])
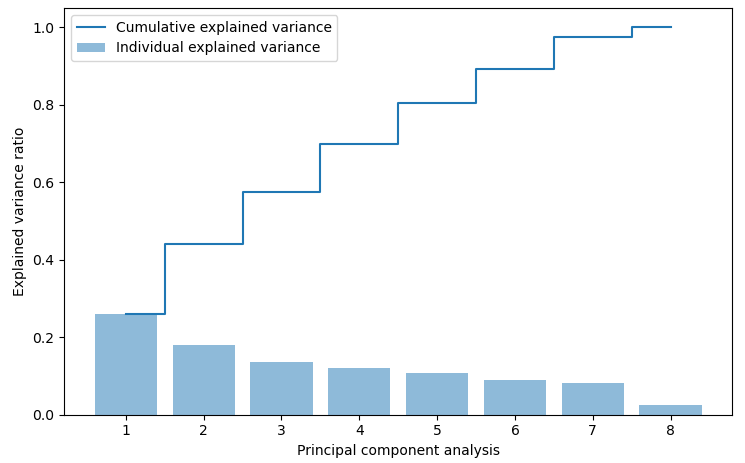
1.1.2. Total variance ratio: total_variance_ratio()#
total_variance_ratio() of eigenvalues \(\lambda_j\), is simply the
fraction of an eigenvalue, \(\lambda_j\) and the total sum of the eigenvalues as:
Using the numpy cumsum function, we can then calculate the cumulative sum of explained variance
which can be plotted if plot is set to True via the matplotlib set function.
>>> from watex.analysis import total_variance_ratio
>>> # Use the X value in the example of `extract_pca` function
>>> cum_var = total_variance_ratio(X, view=True)
>>> cum_var
array([0.26091916, 0.44042728, 0.57625294, 0.69786032, 0.80479823,
0.89379712, 0.97474381, 1. ])
1.1.3. Feature transformation: feature_transformation()#
feature_transformation() consists to transform \(X\) into new principal
components after successfully decomposing to the covariances matrices.
>>> from watex.analysis import feature_transformation
>>> # Use the X, y value in the example of `extract_pca` function
>>> Xtransf = feature_transformation(X, y=y, positive_class = 2 )
>>> Xtransf[0]
array([-1.0168034 , 2.56417088])
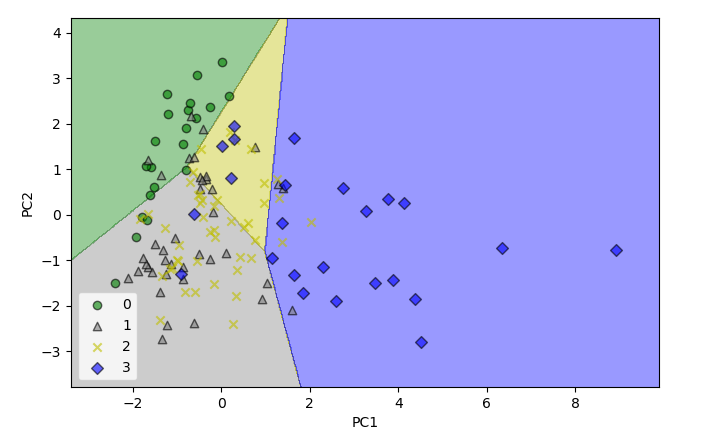
1.1.4. Decision region: decision_region()#
decision_region() displays the decision region for the training data reduced
to two principal component axes.
>>> from watex.datasets import fetch_data
>>> from watex.exlib.sklearn import SimpleImputer, LogisticRegression
>>> from watex.analysis.decomposition import decision_region
>>> data= fetch_data("bagoue original").get('data=dfy1') # encoded flow categories
>>> y = data.flow ; X= data.drop(columns='flow')
>>> # select the numerical features
>>> X =selectfeatures(X, include ='number')
>>> # imputed the missing data
>>> X = SimpleImputer().fit_transform(X)
>>> lr_clf = LogisticRegression(multi_class ='ovr', random_state =1, solver ='lbfgs')
>>> Xpca= decision_region(X, y, clf=lr_clf, split = True, view ='Xt') # test set view
>>> Xpca[0]
array([-1.02925449, 1.42195127])
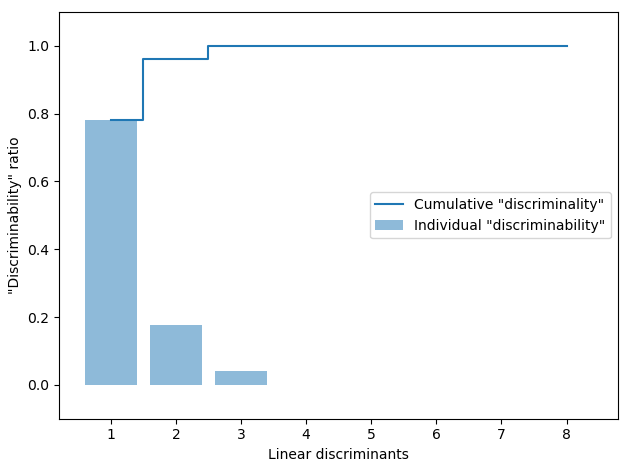
1.1.5. Linear Discriminant Analysis: linear_discriminant_analysis()#
Linear Discriminant Analysis (LDA) is used as a technique for feature extraction to increase the computational efficiency and reduce the degree of overfitting due to the curse of dimensionality in non-regularized models. The general concept behind LDA is very similar to the principal component analysis (PCA), but whereas PCA attempts to find the orthogonal component axes of minimum variance in a dataset, the goal in LDA is to find the features subspace that optimizes class separability.
mathematical details
The main steps required to perform LDA are summarized below:
Standardize the d-dimensional datasets (\(d\) is the number of features)
For each class, compute the \(d-\) dimensional mean vectors. Thus for each mean feature value, \(\mu_m\) with respect to the examples of class \(i\):
Construct the between-clas scatter matrix, \(S_B\) and the within class scatter matrix, \(S_W\). Individual scatter matrices are scaled \(S_i\) before we sum them up as scatter matrix \(S_W\) as:
The within-class is also called the covariance matrix, thus we can compute the between-class scatter matrix \(S_B\) as:
where \(m\) is the overall mean that is computed including examples from all classes.
Compute the eigenvectors and corresponding eigenvalues of the matrix \(S_W^{-1}S_B\).
Sort the eigenvalues by decreasing order to rank the corresponding eigenvectors
Choose the \(k\) eigenvectors that correspond to the \(k\) largest eigenvalues to construct \(dxk\)-dimensional transformation matrix, \(W\); the eigenvectors are the columns of this matrix.
Project the examples onto the new_features subspaces using the transformation matrix \(W\).
>>> from watex.datasets import fetch_data
>>> from watex.utils import selectfeatures
>>> from watex.exlib.sklearn import SimpleImputer, LogisticRegression
>>> from watex.analysis.decomposition import linear_discriminant_analysis
>>> data= fetch_data("bagoue original").get('data=dfy1') # encoded flow
>>> y = data.flow ; X= data.drop(columns='flow')
>>> # select the numerical features
>>> X =selectfeatures(X, include ='number')
>>> # imputed the missing data
>>> X = SimpleImputer().fit_transform(X)
>>> Xtr= linear_discriminant_analysis (X, y , view =True)
1.2. Dimensionality: dimensionality#
Reduces the number of dimensions down to two (or to three) for instance, make it possible to plot high-dimension training set on the graph and often gain some important insights by visually detecting patterns, such as clusters.
1.2.1. Normal Principal Component Analysis (nPCA ): nPCA()#
nPCA() is by far the most popular dimensional reduction algorithm. First, it identifies the hyperplane that
lies closest to the data and projects it to the data onto it.
>>> from watex.analysis.dimensionality import nPCA
>>> from watex.datasets import fetch_data
>>> X, _= fetch_data('Bagoue analysed data')
>>> pca = nPCA(X, 0.95, n_axes =3, return_X=False) # returns PCA object
>>> pca.components_
>>> pca.feature_importances_
[('pc1',
array(['magnitude', 'power', 'sfi', 'geol', 'lwi', 'shape', 'type',
'ohmS'], dtype='<U9'),
array([ 0.6442, 0.5645, 0.4192, 0.2028, 0.1517, 0.1433, 0.0551,
-0.0536])),
('pc2',
array(['shape', 'ohmS', 'sfi', 'lwi', 'type', 'power', 'geol',
'magnitude'], dtype='<U9'),
array([-0.7317, 0.5239, 0.311 , 0.2077, -0.1481, -0.1286, 0.0965,
0.0501])),
('pc3',
array(['lwi', 'shape', 'ohmS', 'type', 'magnitude', 'power', 'sfi',
'geol'], dtype='<U9'),
array([-0.6098, -0.5725, -0.4287, 0.2619, 0.1763, 0.1004, -0.0819,
0.0065]))]
1.2.2. Incremental PCA (iPCA): iPCA()#
iPCA() allows splitting the training set into mini-batches and feeding the algorithm one
mini-batch at a time. One problem with the preceding implementation of PCA is that requires
the whole training set to fit in memory for the SVD algorithm to run. This is useful for large
training sets, and also for applying PCA online(i.e, on the fly as a new instance arrives).
>>> from watex.analysis.dimensionality import iPCA
>>> from watex.datasets import fetch_data
>>> X, _=fetch_data('Bagoue analysed data')
>>> Xtransf = iPCA(X,n_components=None,n_batches=100, view=True)
1.2.3. Kernel PCA (kPCA): kPCA()#
kPCA() performs complex nonlinear projections for dimensionality reduction.
Commonly the kernel trick is a mathematical technique that implicitly maps instances into a very high-dimensionality space(called the feature space), enabling non-linear classification or regression with SVMs. Recall that a linear decision boundary in the high dimensional feature space corresponds to a complex non-linear decision boundary in the original space.
>>> from watex.analysis.dimensionality import kPCA
>>> from watex.datasets import fetch_data
>>> X, _=fetch_data('Bagoue analysed data')
>>> Xtransf=kPCA(X,n_components=None,kernel='rbf', gamma=0.04 )
1.2.4. Locally Linear Embedding(LLE): LLE()#
LLE() is a nonlinear dimensionality reduction based on closest neighbors [1]. It is another powerful
non-linear dimensionality reduction(NLDR) technique. It is a Manifold Learning technique that does not
rely on projections like PCA. In a nutshell, works by first measuring how each training instance
library linearly relates to its closest neighbors(c.n.) and then looking for a low-dimensional
representation of the training set where these local relationships are best preserved(more details shortly).
Using LLE yields good results especially when makes it is particularly good at unrolling twisted manifolds,
especially when there is too much noise [2].
>>> from watex.analysis.dimensionality import LLE
>>> from watex.datasets import fetch_data
>>> X, _=fetch_data('Bagoue analysed data')
>>> lle_kws ={
'n_components': 4,
"n_neighbors": 5}
>>> Xtransf=LLE(X,**lle_kws)
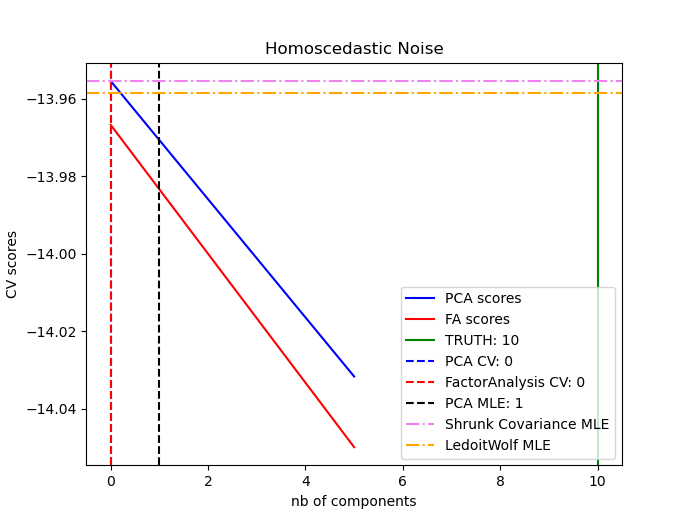
1.3. Model selection with Probabilistic PCA and Factor Analysis (FA): factor#
Probabilistic PCA and Factor Analysis are probabilistic models. The consequence is that the likelihood of new data can be used for model selection and covariance estimation. Here we compare PCA and FA with cross-validation on low-rank data corrupted with homoscedastic noise (noise variance is the same for each feature) or heteroscedastic noise (noise variance is different for each feature). In the second step, we compare the model likelihood to the likelihoods obtained from shrinkage covariance estimators. One can observe that with homoscedastic noise both FA and PCA succeed in recovering the size of the low-rank subspace. The likelihood of PCA is higher than FA in this case. However, PCA fails and overestimates the rank when heteroscedastic noise is present. Under appropriate circumstances, the low-rank models are more likely than the shrinkage models. The automatic estimation from Automatic Choice of Dimensionality for PCA. NIPS 2000: 598-604 by Thomas P. Minka is also compared.
1.3.1. Shrunk covariance scores: shrunk_cov_score()#
shrunk_cov_score() shrunks the covariance scores.
>>> from watex.analysis import shrunk_cov_score
>>> from watex.datasets import fetch_data
>>> X, _=fetch_data('Bagoue analysed data')
>>> shrunk_cov_score (X)
-11.234180833710871
1.3.2. Compare PCA and FA: pcavsfa()#
pcavsfa() Compute PCA score and Factor Analysis scores from
training \(X\) and compare the probabilistic PCA and FA models.
>>> from watex.analysis import pcavsfa
>>> from watex.datasets import fetch_data
>>> X, _=fetch_data('Bagoue analysed data')
>>> pcavsfa (X)
([-13.35021821995266, -13.376979159782895],
[-13.340444115947667, -13.392643293410558])
The output PCA and FA score with homo vs hetero_scedatic noises:
Homo vs Hetero -scedatic data?
Homoscedatic noise data
Heteroscedatic noise data
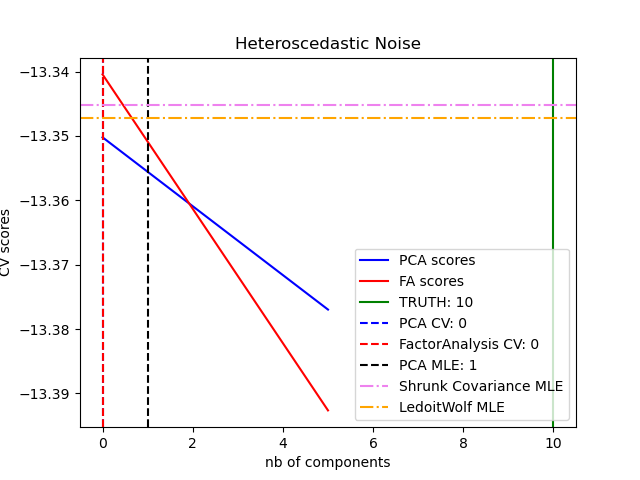
1.3.3. Make Homo/Hetero scedatic noise data: make_scedastic_data()#
make_scedastic_data() generates sampling data for probabilistic PCA
and Factor Analysis model comparison. By default:
nsamples = 1000
n_features = 50
rank =10
>>> from watex.analysis import make_scedastic_data
>>> X, X_homo, X_hetero , n_components = make_scedastic_data ()