Note
Go to the end to download the full example code or to run this example in your browser via Binder
K-Means Featurization#
Featurize data for boosting the prediction and force model to generalization
# License: BSD-3-clause
# Author: L.Kouadio
KMeans Featurisation ( KMF) is a surrogate booster to predict permeability coefficient (k) before any drilling construction. Indeed, KMF creates a compressed spatial index of the data which can be fed into the model for ease of learning and enforce the model capability of generalization. A new predictor based on model stacking technique is built with full target k which balances the spatial distribution of k-labels by clustering the original data.
We start by importing the required modules
import matplotlib.pyplot as plt
from sklearn.datasets import make_moons
from watex.transformers import featurize_X, KMeansFeaturizer
from watex.exlib import train_test_split
from watex.utils import plot_voronoi
Build models with a common data sets. (e.g. Moons dataset)
We generate 8000 samples of dataset where we divided as 50% training and 50% testing For reproducing the same samples of data, we fixed the seed.
seed = 1 # to reproduce the dataset
X0 , y0 = make_moons(n_samples = 8000, noise= 0.2 , random_state= seed )
X0_train, X0_test, y0_train, y0_test = train_test_split (
X0, y0 , test_size =.5, random_state = seed )
Here, there is a shortcut way to featurize data at once by calling the
transformer watex.transformers.featurize_X() to transform X data. It
could also returns KMF_model (kmf_hint) if the parameter return_model is set
to True.
X0_train_kmf, y0_train_kmf = featurize_X(
X0_train, y0_train , n_clusters =200, target_scale =10)
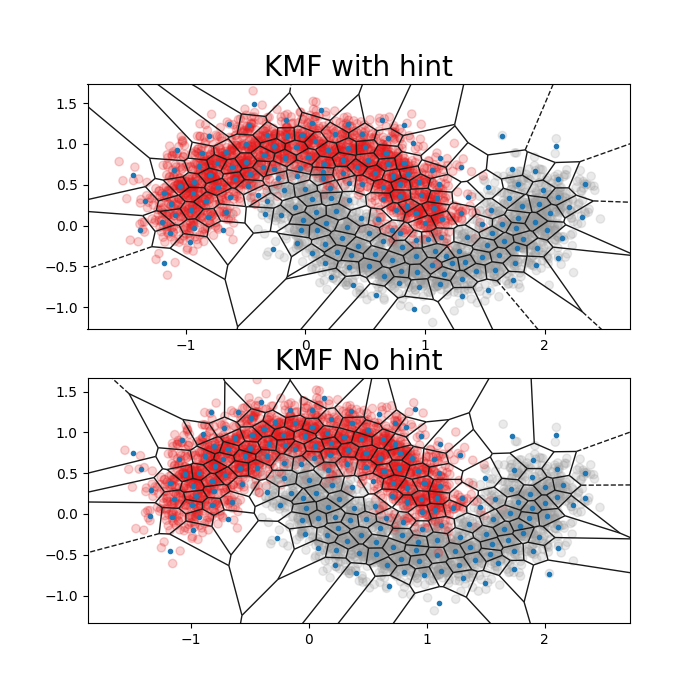
Voronoi plot 2D
Veronoi plot can be used to visualize the model using hint ( target associated) and without. For a human representation ( 2D), we used the most two features importances of the consistent data set.
# Xpca = nPCA( X0_train, n_components= 2 ) # reduce the data set for two most feature components
# X0_test, y0_test = make_moons(n_samples=2000, noise=0.3)
fig, ax = plt.subplots(2,1, figsize =(7, 7))
kmf_hint = KMeansFeaturizer(n_clusters=200, target_scale=10).fit(X0_train,y0_train)
kmf_no_hint = KMeansFeaturizer(n_clusters=200, target_scale=0).fit(X0_train, y0_train)
plot_voronoi ( X0_train, y0_train ,cluster_centers=kmf_hint.cluster_centers_,
fig_title ='KMF with hint', ax = ax [0] )
plot_voronoi ( X0_train, y0_train,cluster_centers=kmf_no_hint.cluster_centers_,
fig_title ='KMF No hint' , ax = ax[1])
<AxesSubplot:title={'center':'KMF No hint'}>
As shown in the figure above. The number of clusters when target information is missed span too much of the space between the two classes. Commonly KMF demonstrates its usefulness when cluster boundaries align with class boundaries much more closely.
Total running time of the script: ( 0 minutes 8.712 seconds)